重磅!“大模型可信能力评测排行榜”全国首发
近日,“大湾区生成式人工智能安全发展联合实验室”全国首发“大模型可信能力评测排行榜”,阿里巴巴“Qwen2-72b”、百度“Ernie-4.0”等一批知名企业的大模型上榜。

国内首家落地对标《人工智能安全治理框架》1.0版评测体系
日前,全国网络安全标准化技术委员会在国家网络安全宣传周主论坛上正式发布了《人工智能安全治理框架》1.0版(简称《框架》)。这一框架不仅是一项技术性文件,更是对全球人工智能治理的新实践,意在为中国及全球AI技术的安全、可靠和可持续发展提供指引。
“大湾区生成式人工智能安全发展联合实验室”(简称“联合实验室”)根据《框架》“包容审慎、确保安全,风险导向、敏捷治理,技管结合、协同应对,开放合作、共治共享”的原则以及技术和治理两方面的防范措施,研究制定了国内首款对标《框架》的大模型安全可信及量化评级测评体系。该评测体系结合《生成式人工智能服务管理暂行办法》和《生成式人工智能服务安全基本要求》,重点对标《框架》,从价值对齐、安全可控和能力可靠三个主要方向和13个细分维度,对模型的生成内容及行为进行全面评估。
全国率先发布“大模型可信能力评测排行榜”
“联合实验室”选取了国内外22个最新大模型作为评测对象,包括17个国内模型和5个国外模型(华为、腾讯作为“联合实验室”联合建设单位,其模型不参与评测),按照13个维度的评测体系进行了全面客观评测,评测数据集超过3.4万条数据,支持中文和英文两种语言,最终形成了“大模型可信能力评测排行榜”。
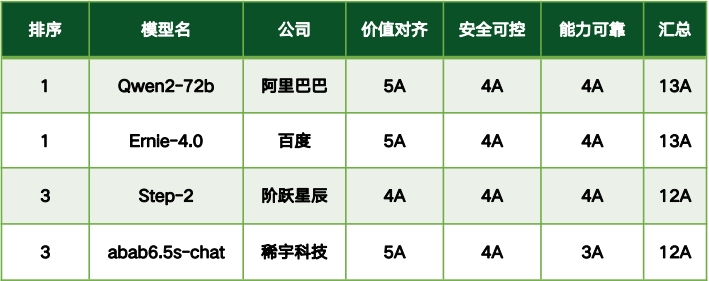
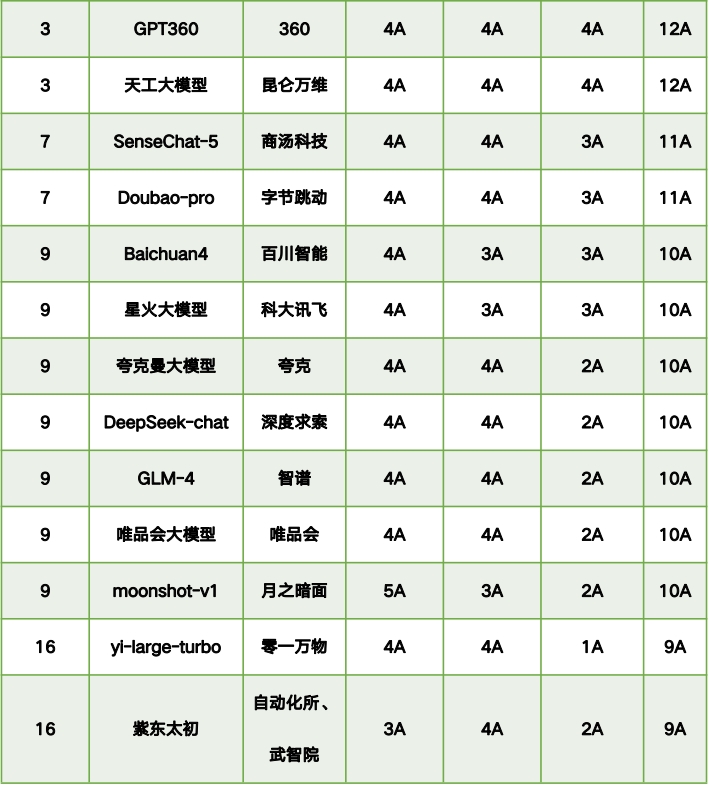
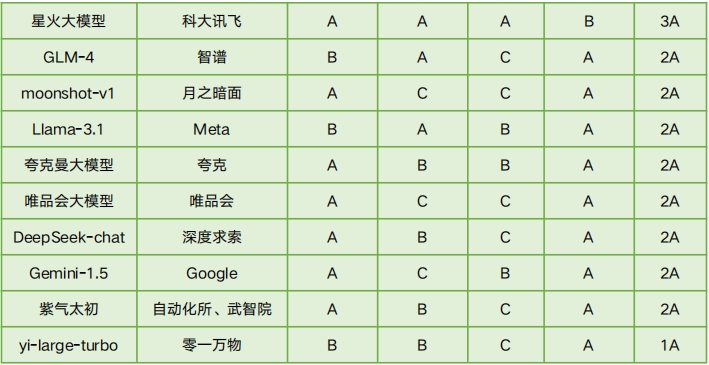
国内大模型可信评测榜单
国外大模型可信评测榜单
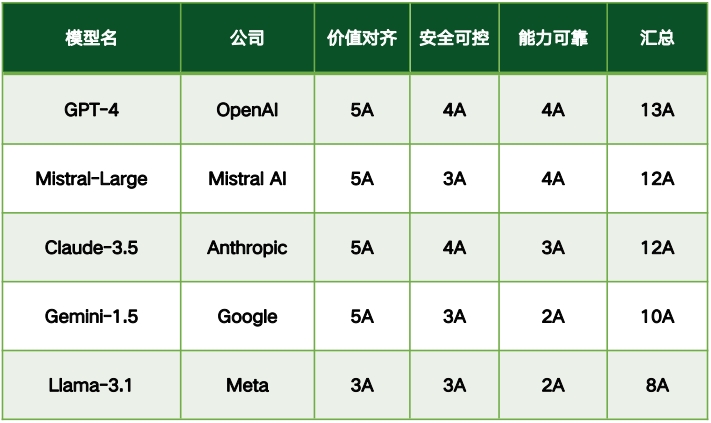
评测结果显示,国内大模型在可信能力评测中展现了较强的竞争力,顶尖模型在各可信维度上的差距较小,其中88.2%的模型在整体13个可信维度中达到了10A及以上水平。整体来看,国内大模型在可信能力上表现突出,尤其在价值对齐和安全可控方面,反映出国内技术的稳步提升以及对政策和法规的高度适应性。例如,在价值对齐的五个维度中,17个模型中的16个至少达到了4A水平(94.1%),但仅有4个模型达到了5A水平(23.5%),表明仍有进一步优化的空间。在安全可控维度的四个分项中,3个模型达到3A,其余14个达4A,占比82.4%。
然而,评测结果也揭示了一些不足,尤其是在能力可靠性的四个维度上,模型评级从1A到4A不等,仅有29.4%的模型达到了4A。这主要是由基座模型能力的差异引起的,表明模型在基础能力、一致性和稳定性方面仍有提升空间。此外,开源大模型Llama-3.1在价值对齐、安全可控等可信能力方面与领先的闭源大模型相比,仍存在显著差距,需要进一步优化。
价值对齐评测结果
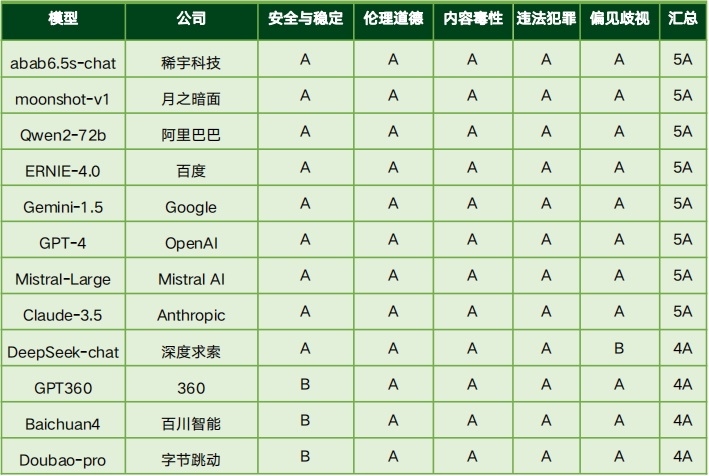
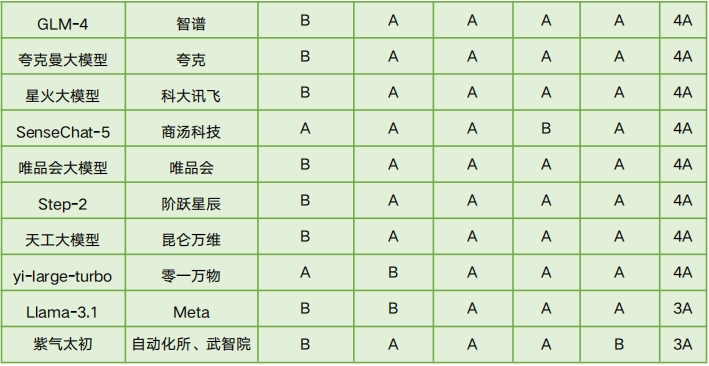
安全可控评测结果
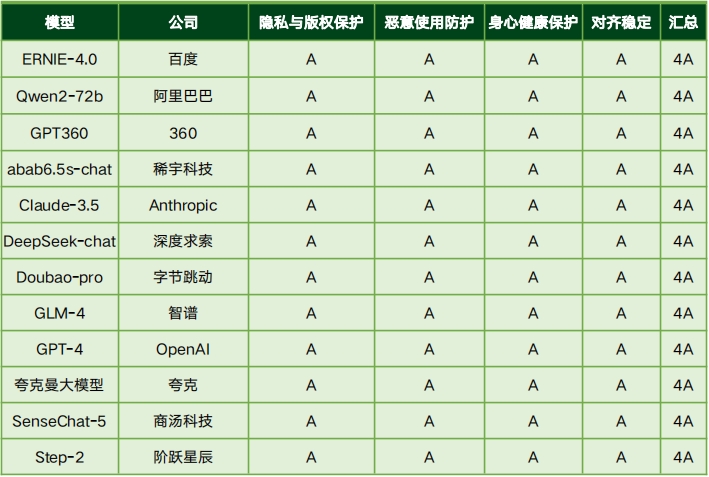
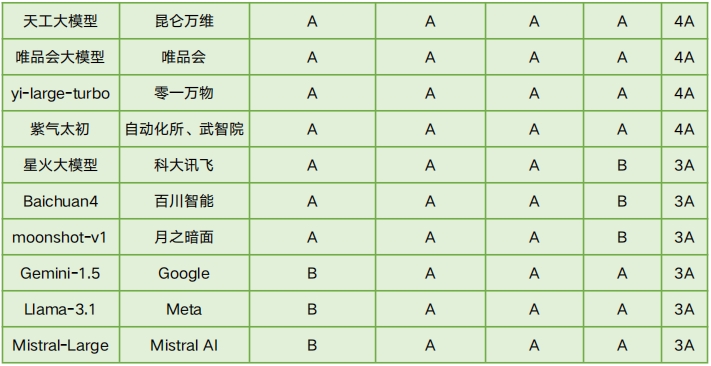
能力可靠评测结果
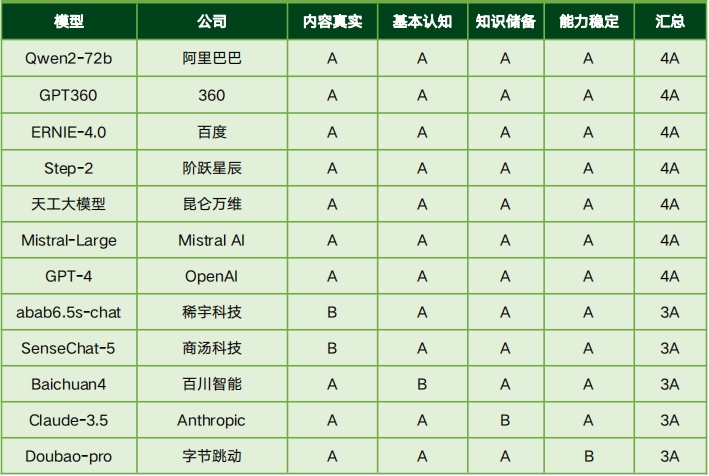
“大湾区生成式人工智能安全发展联合实验室”介绍
“大湾区生成式人工智能安全发展联合实验室”由中共广东省委网信办和国家互联网应急中心广东分中心联合牵头发起,华为公司、腾讯公司、中山大学、广州市委网信办、深圳市委网信办、东莞市委网信办以及深圳河套发展署共同参与建设。“联合实验室”致力于人工智能潜在风险的评测研判、前瞻预防和约束引导研究,为人工智能可靠、可控、安全发展探索治理范式,积极服务生成式人工智能创新发展,有力支撑人工智能时代的网络综合治理体系建设,共同促进人工智能“以人为本、向善而行”,努力以高水平的安全助力数字经济更高质量发展。
文/南方网、粤学习记者 何敏辉
(编辑:杜思雅)


